
Consider Django. Why do we use it? Django serves as a powerful back-end framework that handles client-side requests, processes them, and returns responses. But what happens when a request takes longer to process? Delayed responses can impact the client-side experience, leading to frustration and poor performance for your web application. This is where scheduling tools come into play. A scheduler can help offload time-consuming tasks by handling them periodically or asynchronously, improving overall user experience and reducing the server’s load.
While Django doesn’t come with built-in scheduling capabilities, you can rely on external libraries like Celery Beat, AP Scheduler, and Cloud Scheduler to effectively manage and schedule tasks, ensuring smoother operations and better client-side responsiveness.
- Key Considerations:
-
-
- Complexity of Tasks: For simple tasks, Django Q or APScheduler might suffice. For complex workflows and distributed processing, Celery Beat and Cloud Scheduler is often preferred.
- Scalability: If you need to distribute tasks across multiple workers, Celery Beat is a strong contender.
- Integration: Choose a scheduler that integrates well with your existing Django project and infrastructure.
- Maintainability: Consider the ease of configuration, monitoring, and maintenance of the chosen scheduler.
-
-
- When to use schedulers:
Schedulers are an essential tool in computing that allows you to automate repetitive tasks and tasks that we have to perform at specific times.-
-
- Automate repetitive tasks: Consider the following scenario: we need to create reports at predetermined intervals. To accomplish this, we must utilise schedulers, which are simple to use and manage.
- Executing tasks at specific times and specific intervals: Schedulers help you save time and money by automating tasks. Schedulers can be used to run jobs automatically rather than by hand. For instance, you can use an interval scheduler such as AP Scheduler to set a 10-minute interval if you need to add data to a table every ten minutes. After that, there will be no need to manually execute the script because the scheduler will automatically input the data every ten minutes. This guarantees that the task is completed precisely and consistently while also freeing up your time.
- Triggering Tasks Based on Events: Imagine a system that processes uploaded images. When a user uploads a photo, it’s saved to a specific folder. A scheduled task, perhaps using a file system watcher, could be triggered as soon as a new file arrives in that folder. The task would then automatically resize the image, create thumbnails, and store the processed versions, ready for display on the website.
-
-
- When NOT to use schedulers: While Schedulers are powerful tool but they are not the best solution always.
-
-
- Real-time tasks: if a task needs to respond immediately to user, then the scheduler is not a good choice. Schedulers are designed for background or delayed processing. For example, when a user clicks a button, the response should be immediate, not scheduled.
- One-off tasks: If you only need to run any task only once, and this is a simple operation, manually executing is simpler than a scheduled task. Creating a scheduled task adds overhead, so it’s not worth it for very simple, one-time operations.
- Over-complex scheduling requirement: if your process depends on failure/success of other tasks then the scheduler is not the best choice. In such cases, a dedicated workflow management system might be more appropriate.
-
-
Let’s start with AP Scheduler and Cloud Scheduler:
- AP Scheduler:
A package called AP Scheduler, or Advanced Python Scheduler, lets you plan when Python functions will run at particular intervals or times. It has two main scheduler types: Background Scheduler, which runs tasks in the background without interfering with the main program, and Blocking Scheduler, which stops the current thread until scheduled activities are finished. Because it ensures that the web server stays responsive while managing scheduled tasks, Background Scheduler is especially well-suited for Django applications.
- Using AP Scheduler in Django for Firestore Data Management:
We are taking an example in which we are using Django+apscheduler+firestore. In an application where we are dealing with large numbers of incident data, it’s very difficult to ensure that the database remains optimised and clutter-free. If we are storing incident data in a Firestore collection named incident but only need to keep records for the last 30 days, we have to implement a mechanism in which we archive older incidents.
A practical solution is to use AP Scheduler and schedule a background job that can automatically move older data to an archived incident collection every day at a specific time. This approach ensures that our Incident collection remains lightweight, improving performance and query efficiency.
-
-
- Project Setup (if not already done): Ensure you have a Django project set up.
- Configure your DB Setting:
-
-
-
-
- Make sure you have Google Firestore set up in your Django project.
- Add the Firestore credentials in settings.py.

-
-
-
-
- Create a .py file in apps (if not already created):
-
-
-
-
- Create a new file named scheduler.py in your apps.
-
-
-
-
- Install apscheduler:
-
-
-
-
- Install the apscheduler library using pip:

- Install the apscheduler library using pip:
-
-
-
-
- Write the APScheduler Job:
-
-
-
-
- Create a scheduler.py file in your Django apps and here write your scheduler and its job.
- Here we write a function archive_old_incidents in which we define we have to move incidents older than 30 days to the ‘Archived_Incidents’ collection.
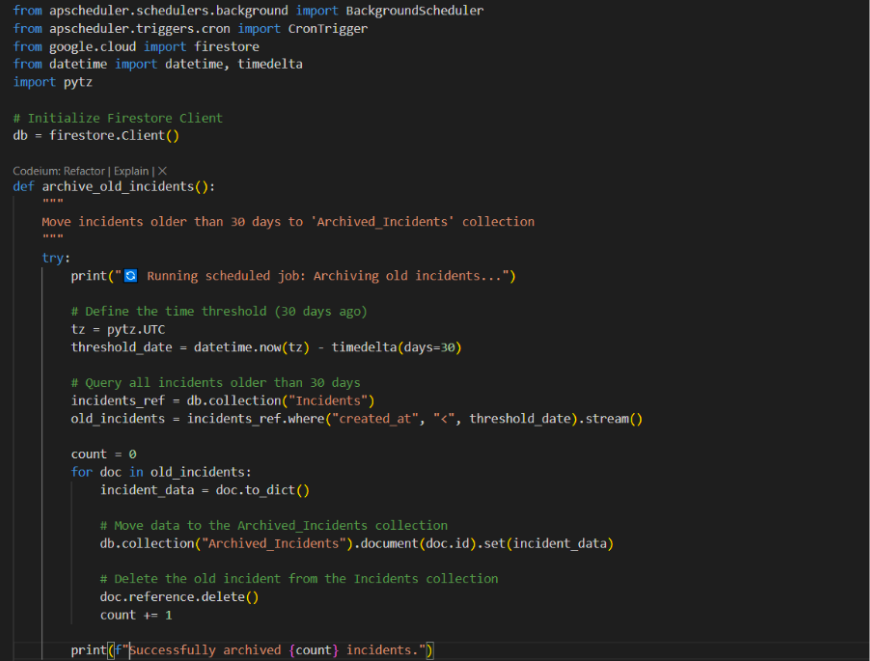
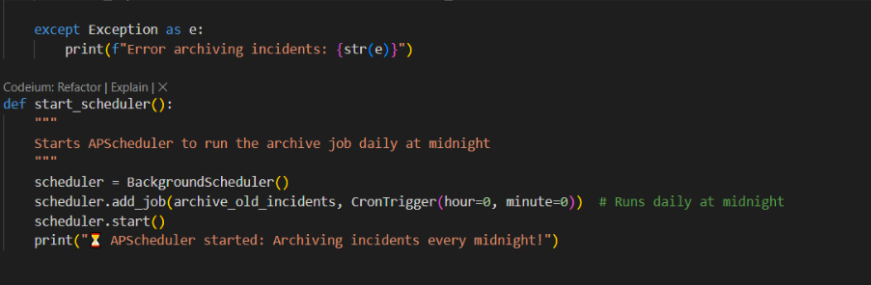
-
-
-
-
- Modify apps.py to Start APScheduler: In your Django app, open apps.py and update it:
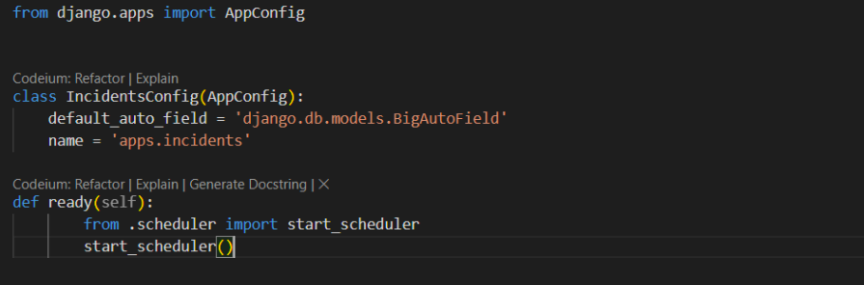
- Modify apps.py to Start APScheduler: In your Django app, open apps.py and update it:
-
-
-
- How this task operates: In this solution, incident data older than 30 days is automatically moved to an archive collection in Firestore using the apscheduler in Django. The start_scheduler() function from scheduler.py is called by the ready() method in apps.py when Django starts, initialising a background scheduler. A cron task is then configured by the scheduler to run daily at midnight (00:00). The archive_old_incidents() function runs at the appointed time, retrieving all incidents older than 30 days from the Incidents collection. After that, these events are removed from the original collection and copied to the Archived_Incidents collection.
- Cloud scheduler: Google Cloud’s Cloud Scheduler managed cron job service, you can schedule tasks by setting up scheduled triggers for HTTP/S endpoints, Pub/Sub topics, or App Engine services.
-
-
-
- Using Cloud Scheduler for Firestore Data Management:
-
-
-
-
- Prepare the Target:
-
-
-
-
-
-
- Before creating a Cloud Scheduler job, decide what action you want to automate. Common options.
- HTTP/S Endpoint: A Cloud Function or external API.
- Pub/Sub Topic: To send messages to other Google Cloud services.
- App Engine Service: If you’re using App Engine applications.
- For this example, let’s automate a Cloud Function that archives old Firestore data.
-
-
-
2. Deploy the Cloud Function:
-
-
-
-
- Write and deploy a Cloud Function that performs the task. For example, a function that moves data older than 30 days from data to archive collections in Firestore:
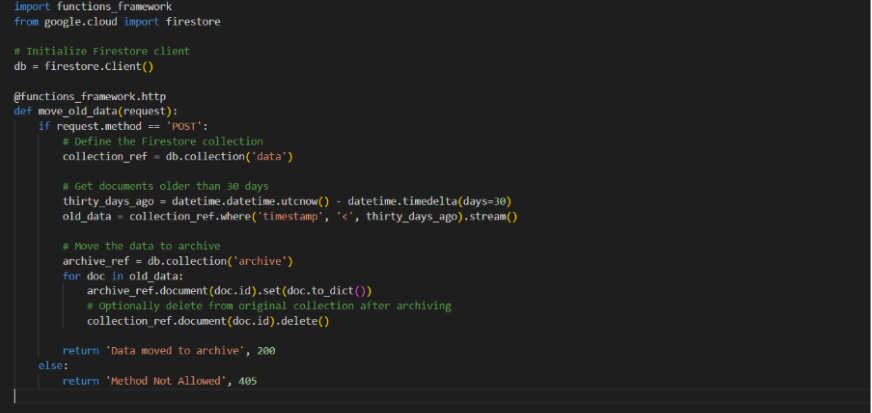
- Open the terminal or use Cloud Shell in Google Cloud Console and Navigate to the folder containing your function code.

- Replace FUNCTION_NAME and HTTP method according to your need and after deployment, note the generated HTTP/S trigger URL.
- Write and deploy a Cloud Function that performs the task. For example, a function that moves data older than 30 days from data to archive collections in Firestore:
-
-
-
3. Enable Cloud Scheduler API:
-
-
-
- Go to the Cloud Scheduler API page.
- Click Enable.
-
-
4. Create a Cloud Scheduler Job:
-
-
-
-
- Go to Cloud Scheduler: In the Google Cloud Console, search for Cloud Scheduler and navigate to it.
- Click “Create Job”:
-
- Name your job (e.g. move_old_data).
- Select a region close to your resources (Cloud Functions, Pub/Sub, etc.).
-
-
-
-
-
-
-
-
- Set Frequency: Use a cron expression to define when the job runs. For example:
-
- 0 0 * * *: Every day at midnight (UTC).
- Choose the time zone that matches your requirements.
-
- Set Frequency: Use a cron expression to define when the job runs. For example:
-
-
-
-
-
-
-
- Set Target Type:
-
- For this example, select HTTP.
- URL: Paste your Cloud Function URL (e.g., https://REGION-PROJECT_ID.cloudfunctions.net/move_old_data).
- HTTP Method: Select GET or POST (POST in our case).
- Headers: Add any required headers if necessary.
-
- Set Target Type:
-
-
-
-
-
-
-
- Authentication:
-
- If your Cloud Function requires authentication:
- Choose Service Account and select a suitable service account with access to your Cloud Function.
- If your Cloud Function is public (allow-unauthenticated), no authentication is needed.
-
- Authentication:
-
-
-
5. Save the Job:
-
-
-
-
- Click Create. Your job will now appear in the Cloud Scheduler dashboard.
-
-
-
6. Verify the Job:
-
-
-
-
- Click on your job in the Cloud Scheduler dashboard and select Run Now to trigger it manually.
- Check the Cloud Function logs in the Logs Explorer to verify that the job ran successfully.
-
-
-
7. Logs: Check execution logs in Cloud Scheduler and Cloud Functions.
8. Retries: If a job fails, Cloud Scheduler automatically retries based on the configured retry policy. You can customize this policy.
9. Alerts: Set up monitoring alerts using Google Cloud Monitoring for job failures.
- How this Task Operates: We are using Google Cloud Scheduler to schedule tasks in Firestore, including automating data lifecycle management operations like archiving obsolete data. For example, to maximize speed and storage expenses, you may want to move documents older than 30 days to an archive collection if you have a Firestore collection holding active data (such as user activity logs or temporary records). Deploying a Cloud Function that searches the Firestore database, finds records older than the designated period, and adds them to the archive collection will do this. After this Cloud Function is deployed, you may use Google Cloud Scheduler to use an HTTP endpoint to trigger it on a regular basis, such every day or every week. With this completely managed configuration, you can schedule tasks without having to worry about maintaining your own server, guaranteeing scalability and stability. Time savings, fewer manual labor, and effective data management are all made possible by the seamless automation made possible by the combination of Firestore, Cloud Functions, and Cloud Scheduler.
- Comparison between APScheduler and Cloud Scheduler:
| Aspects | AP Scheduler | Cloud Scheduler |
| Nature | Python-based library for scheduling tasks in local applications. | Fully managed cloud-native scheduling solution by Google Cloud. |
| Implementation | Scheduling logic is embedded in a Python script. | Triggers tasks via HTTP endpoints, typically handled by Cloud Functions or other services. |
| Hosting | Requires hosting and maintaining the application environment. | Google manages the infrastructure, with no need for server maintenance. |
| Reliability | Relies on the uptime of the host server; lacks automatic retries for failed tasks. | High reliability with automatic retries for failures. |
| Use Case | Best suited for smaller, independent, or local projects where flexibility is a priority. | Ideal for scalable, production-grade applications requiring availability, reliability, and minimal maintenance. |
| Maintenance | Requires manual server and application upkeep. | Maintenance-free, as Google handles all infrastructure. |
| Scalability | Limited by the resources of the host server. | Scales seamlessly with other Google Cloud services. |
| Integration | Standalone or local use with minimal external dependencies. | Seamlessly works with Google Cloud services. |
| Suitability | Suitable for local or isolated projects requiring flexibility and lightweight scheduling. | Designed for production-ready, cloud-based environments with a focus on reliability and efficiency. |
- Conclusion– Transitioning from APScheduler to Google Cloud Scheduler represents a smarter approach to managing scheduled tasks, especially in cloud-native and production-grade environments. While APScheduler is suitable for smaller, self-contained applications that prioritize simplicity and flexibility, it requires developers to host and maintain the application environment. This makes it less ideal for scenarios where uptime and reliability are critical.
Google Cloud Scheduler, on the other hand, provides a robust and efficient solution for tasks like Firestore data archiving. Its key features—such as reliability, automated retries, and seamless integration with Google Cloud services like Cloud Functions, Firestore, and Pub/Sub—ensure your workflows operate smoothly at scale. Achieving these benefits with Google Cloud Scheduler is straightforward:- Reliability: Google Cloud Scheduler operates on fully managed infrastructure, reducing the risk of downtime and ensuring consistent performance.
- Automated Retries: The platform automatically retries failed tasks, minimizing the risk of missed executions without requiring manual intervention.
- Seamless Integration: By leveraging Cloud Functions for task execution, Firestore for database operations, and Pub/Sub for event-driven workflows, you can create a tightly integrated ecosystem that simplifies complex scheduling tasks.
By shifting to Google Cloud Scheduler, you can offload infrastructure management, improve task reliability, and scale effortlessly, making it the ideal choice for modern, production-grade applications.

Himanshi Rohilla
Software Engineer
Himanshi is a software engineer, adapt at developing efficient and scalable applications. She is passionate about optimizing systems, implementing best practices, and staying ahead of emerging technologies. Beyond coding, Himanshi is a collaborative team player, always eager to share knowledge and contribute to a positive work environment.

