
Introduction: The Real Bottleneck in Public Procurement Isn’t Submission — It’s Judgment
Over the last decade, governments across the world have invested heavily in digitising public procurement. E-tender portals, online submissions, digital bid openings, and transparency dashboards are now standard.
And yet, procurement outcomes continue to suffer.
Ask any procurement officer, vigilance authority, or audit body where the system still breaks down, and the answer is remarkably consistent:
“Evaluation takes too long, depends too heavily on manual reading, and exposes us to audit and litigation risk.”
Digitisation solved how bids are submitted.
It did not solve how bids are evaluated.
This gap — between digital intake and human-intensive judgment — is where procurement delays, inconsistencies, and disputes originate. It is also why tender evaluation has emerged as the single highest-impact use case for Generative AI in government, ahead of citizen chatbots, HR automation, or financial analytics.
Not because evaluation is flashy.
But because it is foundational to governance, fiscal discipline, and public trust.
Tender Evaluation Is a Cognitive Governance Problem — Not a Workflow Problem
Public procurement evaluation is often treated as an operational task. In reality, it is one of the most cognitively demanding functions in government.
Evaluation committees are required to:
- Read thousands of pages across technical, financial, and legal submissions
- Interpret nuanced eligibility clauses and compliance conditions
- Compare vendors across heterogeneous formats and narratives
- Identify deviations, exceptions, and conditional responses
- Justify scores and decisions in writing
- Defend outcomes during audits, vigilance inquiries, and legal challenges
This is knowledge work under regulatory pressure, not data entry.
Research from the OECD and the World Bank consistently highlights that procurement failures are rarely caused by lack of rules — they are caused by information overload, interpretational inconsistency, and documentation gaps.
Generative AI is uniquely suited to this problem because it is designed for cognitive augmentation:
- Reading
- Interpretation
- Cross-comparison
- Reasoning
- Explanation
In other words, tender evaluation is not just compatible with GenAI — it is structurally aligned to it.
Why Evaluation Delivers the Highest ROI of Any AI Use Case in Procurement
Across global procurement systems, evaluation stands out as the costliest, riskiest, and most delay-prone phase.
A. Evaluation Consumes the Majority of Human Effort
Multiple public-sector modernisation studies (including World Bank GovTech diagnostics) show that 60–70% of total procurement effort is concentrated in evaluation — reading bids, cross-referencing clauses, drafting justifications, and responding to clarifications.
Automation elsewhere yields marginal gains.
Automation here fundamentally shifts capacity.
B. Evaluation Carries the Highest Audit and Litigation Risk
Supreme Audit Institutions globally — including CAG in India, NAO in the UK, and GAO in the US — repeatedly flag evaluation as the weakest link in procurement defensibility.
Why?
Because:
- Decisions are poorly documented
- Reasoning is inconsistent across evaluators
- Source references are hard to trace post-fact
One missed clause can invalidate an entire tender.
GenAI directly addresses this by creating evidence-linked, explainable evaluation trails — something manual processes struggle to sustain at scale.
C. Evaluation Suffers Most from Human Variability
Two committees evaluating the same bid often reach different interpretations — not due to bias, but due to fatigue, cognitive overload, and subjective emphasis.
OECD procurement guidelines emphasise consistency and repeatability as core principles of fair procurement.
GenAI introduces a baseline of interpretational consistency, without removing human authority.
D. Evaluation Handles the Highest Document Complexity
Modern tenders include:
- Scanned PDFs
- Annexures
- Financial tables
- Technical diagrams
- Certificates and declarations
This multimodal complexity is precisely where traditional rule-based automation fails — and where GenAI-powered document intelligence succeeds.
E. Evaluation Dictates Overall Procurement Cycle Time
World Bank studies show that evaluation delays are the primary driver of procurement overruns, leading to:
- Project delays
- Cost escalation
- Lapsed budgets
Speeding up evaluation does not just save time — it protects public value.
What GenAI Enables in Evaluation That Was Previously Impossible
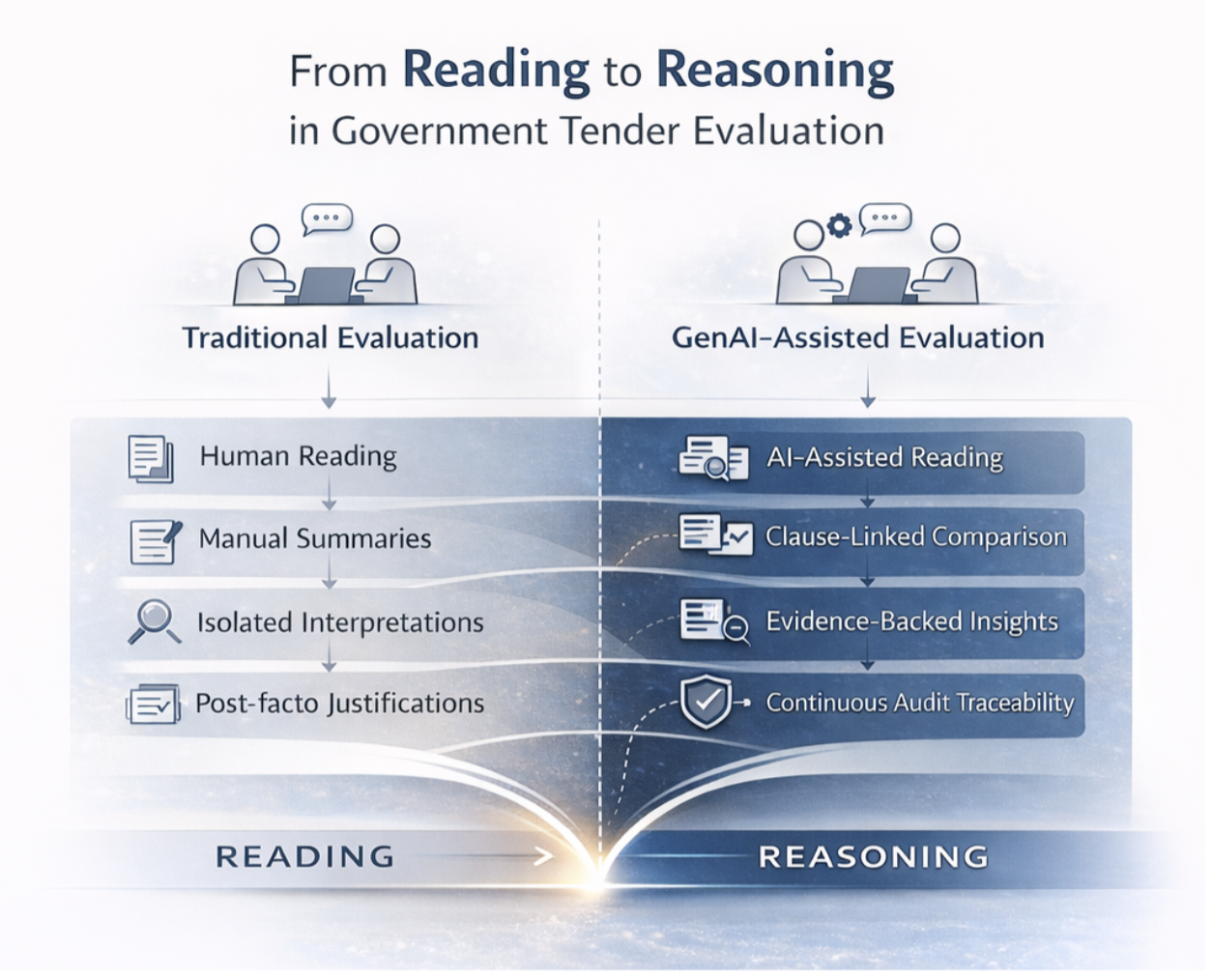
This is not incremental automation. It is a qualitative shift in how evaluation is conducted.
1. Reading at Government Scale
GenAI can ingest and reason over thousands of pages in minutes, structuring insights by clause, requirement, and bidder — something no human committee can do without weeks of effort.
2. True Vendor-to-Vendor Comparison
Instead of manual summaries, GenAI enables:
- Clause-by-clause comparison
- Side-by-side interpretations
- Highlighting deviations and conditional responses
This level of comparative clarity simply did not exist earlier.
3. Automated Eligibility and Compliance Mapping
GenAI can map bidder responses directly to eligibility criteria, with explicit citations back to source documents — a critical requirement for audit defensibility.
4. Assisted Technical Scoring — Not Automated Decisions
Importantly, GenAI does not replace evaluators.
It:
- Suggests scores
- Provides structured justifications
- Surfaces risks and gaps
Final decisions remain firmly with committees — aligning with global principles of responsible AI in government (OECD, WEF).
5. Audit-Ready Evaluation Logs by Design
Every insight, comparison, and score is traceable.
This directly strengthens:
- Vigilance processes
- CAG audits
- Legal defensibility
Why Governments Trust GenAI in Evaluation More Than Other Use Cases
Governments are cautious adopters — rightly so.
Tender evaluation is gaining trust faster than other GenAI applications because:
- Human authority remains intact
- Every output is explainable and traceable
- Governance outcomes improve, not just efficiency
- Deployments can be fully sovereign and air-gapped
This aligns with global public-sector AI frameworks from OECD, WEF, and national digital governance bodies.
Why Most AI Vendors Fail at Tender Evaluation — And Why Valiance Doesn’t
Tender evaluation is not a generic AI problem.
It requires deep domain + deep technology, simultaneously.
Most vendors bring one — rarely both.
Effective evaluation AI demands:
- Procurement law and process understanding
- Domain-specific document reasoning
- Multimodal document intelligence
- Secure, sovereign deployment architectures
- Workflow alignment with real evaluation committees
Valiance’s advantage comes from real-world implementation at national scale, not lab prototypes.
What differentiates Valiance:
✔ Proven deployment in one of India’s largest evaluation systems
✔ Domain-trained models designed specifically for procurement language
✔ Ability to process real Indian tender formats — scanned PDFs, annexures, tables, certificates
✔ Evaluation workflows that mirror actual committee processes
✔ Secure, sovereign, air-gapped architectures suitable for sensitive tenders
This is why our systems are not just adopted — they are trusted.
Conclusion: If Governments Could Apply GenAI to Only One Function, It Should Be Tender Evaluation
Because no other use case:
- Saves as much institutional time
- Reduces as much governance risk
- Improves transparency and fairness as directly
- Impacts decisions of such high fiscal value
Globally, governments are realising that AI’s greatest value is not in answering citizen queries — but in strengthening the quality of state decisions.
Tender evaluation sits at the heart of that mandate.
And that is why it is the most valuable GenAI use case in government today — and why Valiance stands uniquely positioned to deliver it at scale.







