Data Lake & Data Warehouse
Drive Intelligence, Innovate and Act Faster with a Centralized Scalable Repository that Unifies Multiple Truths and Versions of Structured and Unstructured Data.
Drive Intelligence, Innovate and Act Faster with a Centralized Scalable Repository that Unifies Multiple Truths and Versions of Structured and Unstructured Data.
Data is used in practically every element of a business today, from product development to marketing, customer assistance, and more. While harvesting data is important, storing it in a safe, scalable, and highly accessible manner is an entirely different issue. Data warehouses and data lakes transform the noise generated by digital data into creative insights. By supporting big data volume and velocity, they inspire an enterprise-wide information revolution that streamlines data input, provides self-service capabilities, and lowers storage and compute costs.
At Valiance, we aim to tackle the productivity and scalability issues that restrict you from realizing the value of your data assets. We provide a solution that satisfies your present and future business requirements. To simplify data management and governance, our team will work with your current IT investments. They also connect operational stores and data warehouses, enabling you to enhance existing data applications.
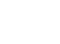
Harness a variety of data in one single repository to drive enterprise-wide innovation using AI & ML
Identify and pursue business growth opportunities faster with a holistic view of enterprise-wide data
Save a variety of data, structured or unstructured, in flexible low-cost data storage for longer periods.
Democratize access to enterprise-wide data within the company driving increased productivity & innovation.
Integrate, standardize and prepare data sources for advanced analytics use cases

Create right sized, optimized & cost effective DL & DW solution with an eye for advanced analytics use cases

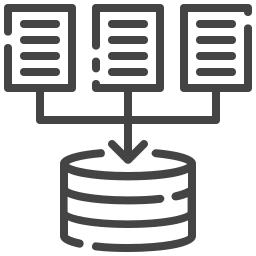
Advisory on Data governance, privacy and security for compliance needs

Expertise in open source & cloud native technologies for storage and data integration

Selection of right tools and platforms in partnerships with hyperscalers & ISV’s.

Managed services model to support upkeep and further enhancement of data platforms
 Ingestion and Integration
Ingestion and Integration
 Cleaning and Normalization
Cleaning and Normalization
 Data Access Control
Data Access Control
 Compliance
Compliance
 Data Streaming
Data Streaming
 Data Warehouse Replacement
Data Warehouse Replacement
 Data Organization and Search
Data Organization and Search
 Data Analytics
Data Analytics

A data lake's landing zone is the optimal spot to combine data across systems in a consolidated repository. It can support a wide range of data ingestion pipelines, from file transfer protocol (FTP) upload to file sharing to relational databases. Connecting various data sources to a lake should be simple and intuitive. Integration tools offer quick connectivity to externally hosted services.

A lake's raw data can be delivered to a data transformation task for cleaning and processing. Custom business rules are frequently followed. De-duplication and normalization are two common use cases.

Data lakes can be designed to provide multiple degrees of access to different stakeholders without duplicating the data.
AWS Lake Formation has an extra security layer that allows for declarative management of access rights (for example, a lake administrator could have unrestricted access while a data analyst would be prevented from accessing personally identifying information (PII) of actual customers).

Consumer privacy laws such as the GDPR and the CCPA allow customers the right to know what data is gathered (the right to know) and if it is to be destroyed (right to delete). A data lake, as the single repository for reporting and data integrations, is an effective regulatory compliance solution.

Near-real-time data collecting for the Internet of Things is one of the most prevalent applications of data lakes (IoT). Streaming data can also be used to feed a data lake. Analytics pipelines designed with data lakes receive streams of video, audio, transaction logs, or communications. Streaming data can thus benefit from continuous reporting that can help with outlier detection for instance.

Data lakes are cheaper than warehouses and can replace them, especially for reporting and if the data is read-only. While data lakes did not previously enable transactional changes, governed tables are available today, and they enable transactions that allow users to enter, remove, and edit data, exactly like a database.

Organizations with hundreds or thousands of data sources require a repository to store and handle all data. Data catalogs in data lakes offer table definitions, database names, and other information. Tags are useful information for tables and columns. Tag taxonomy searches data lake items (databases, tables, columns). Access permissions are also specified through tags.

Data lakes are intended for big data analytics and, more importantly, real-time actions. Data lakes are well-suited to leverage large amounts of data consistently, with algorithms driving (real-time) analytics with rapid data. In addition, we see a movement in business intelligence towards in-data-lake BI solutions. Many firms are looking to implement a data lake with cloud migration.
Discover how Valiance helped an Indian digital engagement solutions company with a 500 mn+ customer base increase its customer engagement through unstructured texts and ML algorithms
Our Winning Moves
Outcome :

Find out how Valiance helped an Indian e-commerce business that connects manufacturers and suppliers with clients and offers B2C, B2B, and C2C sales services update data processing and reporting to generate daily or on-demand reports.
Our Winning Moves
Outcome :
Contact Us to Learn More

